이 문서는 Guide to App Architecture 를 번역한 문서입니다.
앱 아키텍쳐 가이드
이 가이드는 앱 개발의 기본을 경험하고, 안정적인 프로덕션 수준의 앱을 구축하기 위한 권장사항 및 아키텍쳐에 대해 알고싶어하는 개발자를 대상으로 합니다.
Note: 이 가이드는 독자가 Android 프레임워크를 잘 알고 있다고 가정합니다. 앱 개발을 처음하는 경우 이 가이드의 필수 주제를 다루는 시작하기 교육 시리즈를 확인하세요.
앱 개발자가 직면한 문제
대부분 기존 데스크탑의 경우 런처 바로가기에서 단일 진입점을 가지며 단일 모놀리식 프로세스로 실행되는 것과는 달리 Android앱은 훨씬 복잡한 구조를 가지고 있습니다. 일반적인 Android앱은 Activity, Fragment, Service, Content Provider, Bradcase Receiver를 포함하는 app components를 가집니다.
앱 컴포넌트의 대부분은 앱 manifest에 선언됩니다. 앱 manifest는 Android OS에서 앱과 사용자의 기기 전반을 통합하는 방법을 결정하는데 사용됩니다. 앞서 언급했듯이 데스크톱 어플리케이션은 전통적으로 모놀리식 프로세스로 실행되지만 알맞게 구현된 Android 어플리케이션은 사용자가 장치의 다른 어플리케이션을 통해 이동하면서 끊임없이 흐름과 작업을 전환 할 때 훨씬 더 융통성이 있어야합니다.
예를들어, 좋아하는 소셜네트워크 앱에서 사진을 공유 할 때 어떤 일이 발생하는지 생각해보세요. 앱은 Android OS가 카메라 앱을 실행하여 요청을 처리하는 카메라 인텐트를 발생시킵니다. 이 시점에서 사용자는 소셜 네트워크 앱과 작별하지만 경험은 원활합니다. 그러면 카메라 앱이 파일 선택기를 시작하는등 다른 인텐트를 실행하여 다른 앱을 실행 할 수 있습니다. 결국 사용자는 소셜 네트워킹 앱으로 돌아와서 사진을 공유합니다. 또한 사용자는 이 프로세스의 어느 시점에서든 전화 통화를 할 수 있으며 전화를 마친 후 다시 사진을 공유 할 수 있습니다.
Android에서는 앱-호핑(뛰어넘는)동작이 일반적이므로 앱에서 이러한 흐름을 올바르게 처리해야합니다. 모바일 디바이스는 리소스가 제한되어있기 때문에 언제든지 새로운 앱을 실행 할 수 있는 공간을 만들기 위해 운영체제에서 일부 앱을 종료해야 할 수 있습니다.
모든 포인트에서 앱 컴포넌트는 개별적으로 또는 순서에 따라 실행 될 수 있으며, 사용자 또는 시스템에 의해 언제든지 파괴 될 수 있습니다. 앱 컴포넌트는 일시적이며 LifeCycle(생성 및 제거)를 제어 할 수 없기 때문에 앱 컴포넌트에 앱 데이터나 상태를 저장하며 안되며 앱 컴포넌트가 서로 종속되어서는 안됩니다.
일반적인 아키텍쳐 원칙
앱 컴포넌트를 사용하여 앱 데이터 및 상태를 저장 할 수 없는 경우 앱을 어떻게 구성해야할까요?
집중해야 할 가장 중요한 사항은 앱의 관계를 분리하는 것입니다. 모든 코드를 Activity 또는 Fragment에 작성하는 것은 일반적인 실수입니다. UI 또는 OS 상호 작용을 처리하지 않는 코드는 이러한 클래스에 있어서는 안됩니다. 가능한 린 상태로 유지하면 LifeCycle와 관련된 많은 문제를 피할 수 있습니다. 그 클래스(Activity, Fragment)를 소휴가고 있지 않다는 것을 잊지마세요. 그들은 OS와 앱 사이의 계약을 연결하는 접작체 클래스 일 뿐입니다. Android OS는 사용자 상호 작용이나 메모리 부족과 같은 다른 요인에 따라 언제든지 이들을 파괴 할 수 있습니다. 견고한 사용자 환경을 제공하려면 의존성을 최소화하는 것이 가장 좋습니다.
두 번째 중요한 원칙은 모델, 바람직하게는 지속성있는 모델에서 UI를 구동해야 한 다는 것입니다. 지속성은 두 가지 이유로 이상적입니다. OS가 리소스를 확보하기 위해 앱을 파괴거나 네트워크 연결이 불안정하거나 연결되지 않은 경우에도 앱이 계속 작동하는 경우 사용자가 데이터를 잃지 않습니다. 모델은 앱의 데이터를 처리하는 컴포넌트입니다. 그것들은 앱의 뷰 및 앱 컴포넌트와 독립적이므로 해당 컴포넌트의 LifeCycle 문제로부터 격리됩니다. UI 코드를 간단하고 앱 로직이 없도록 유지하면 관리하기가 더 쉽습니다. 잘 정의된 데이터 관리 책음을 지는 모델 클래스에 기반하여 앱을 테스트하면 테스크가 가능하고 앱을 일관성있게 유지 할 수 있습니다.
권장 앱 아키텍쳐
이 세션에서는 유즈-케이스를 통해 작업을 진행하고 아키텍쳐 구성 요소를 사용하여 어플리케이션을 구현하는 방법을 보여줍니다.
Note: 모든 시나리오에 가장 적합한 앱을 구현하는 한 가지 방법은 없습니다. 지금 말하게 될, 이 권장 아키텍쳐는 대부분의 유즈-케이스의 좋은 시작점이 될 수 있습니다. 이미 Android 앱을 구현하는 좋은 방법이 있다면 변경 할 필요가 없습니다.
사용자 프로필을 표시하는 UI를 작성한다고 가정 해 보겠습니다. 이 사용자 프로필은 REST API를 사용하여 백엔드 서버에서 가져옵니다.
사용자 인터페이스 만들기
UI는 Fragment UserProfileFragment.java와 해당 레이아웃 파일 user_profile_layout.xml로 구성됩니다.
UI를 표현하려면, 데이터 모델에 두 개의 데이터 요소가 있어야합니다.
-
User Id : 사용자의 식별자입니다. Fragment 매개변수를 사용하여 Fragmnet에 이 정보를 전달하는것이 가장 좋습니다. Android OS가 프로세스를 파괴하면 이 정보가 보존되어 다음에 앱을 다시 시작할때 ID를 사용 할 수 있습니다.
-
User 객체 : 사용자 데이터를 저장하는 POJO
이 정보를 유지하기 위해 ViewModel 클래스에 기반한 UserProfileViewModel을 생성 할 것입니다.
ViewModel은 Fragment 또는 Activity와 같은 특정 UI 구성요소에 대한 데이터를 제공하고 데이터를 로드하거나 사용자 수정 내용을 전달하기 위해 다른 구성요소를 호출하는등 데이터 처리의 비지니스 부분과의 통신을 처리합니다. ViewModel은 뷰에 대해 알지 못하고 회전으로 인한 Acitivty를 다시 생성하는등의 구성 변경에 영향을 받지 않습니다.
이제 우리는 3개의 파일을 가집니다.
user_profile.xml: UI 정의UserProfileViewModel.xml: UI용 데이터를 준비하는 클래스UserProfileFragment.java: ViewModel에 데이터를 표시하고 사용자 상호작용에 반응하는 UI 컨트롤러
아래는 구현의 일부 소스입니다.(레이아웃 파일은 단순화를 위해 제외되었습니다.)
public class UserProfileViewModel extends ViewModel {
private String userId;
private User user;
public void init(String userId) {
this.userId = userId;
}
public User getUser() {
return user;
}
}
public class UserProfileFragment extends LifecycleFragment {
private static final String UID_KEY = "uid";
private UserProfileViewModel viewModel;
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
String userId = getArguments().getString(UID_KEY);
viewModel = ViewModelProviders.of(this).get(UserProfileViewModel.class);
viewModel.init(userId);
}
@Override
public View onCreateView(LayoutInflater inflater,
@Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
return inflater.inflate(R.layout.user_profile, container, false);
}
}
Note: 위 예제는 Fragment 클래스 대신 LifecycleFragment 클래스를 상속받습니다. Architecure Components의 라이프 사이클 API이 안정되면 Android Support Library의 Fragment 클래스가 LifecycleOwner를 구현합니다.
이제 우리는 3가지 코드 모듈을 가지고 있습니다. 이것은 어떻게 연결이 될까요? ViewModel의 사용자 필드가 설정되면 UI로 알리는 방법이 필요합니다. 이것이 바로 LiveData 클래스가 필요한 시점입니다.
LiveData는 Observable 데이터 홀더입니다. 이 기능을 사용하면 어플리케이션의 구성요소에서 LiveData 객체를 observe 할 수 있습니다. 또한 LiveData는 앱 컴포넌트(Activity, Fragment, Service)의 Lifecycle 상태를 존중하며 앱이 더 많은 메모리를 소비하지 않도록 메모리 릭을 방지하는 올바른 방법을 제공합니다.
Note: RxJava 또는 Agera와 같은 라이브러리를 이미 사용하고 있다면 LiveData 대신 계속 사용할 수 있습니다. 그러나 이러한 방법이나 다른 방법을 사용할 때는 관련 LifecycleOwner이 중지되고 LifecycleOwner이 파괴 될 때 스트림이 일시 정지가 되도록 적절하게 Lifecycle을 처리해야합니다.
android.arch.lifecycle:reactivestreams아티펙트를 추가하여 LiveData를 다른 리엑티브 스트림 라이브러리(예:RxJava2)와 함께 사용할 수 있습니다.
이제 우리는 UserProfileViewModel의 User 필드를 LiveData<User>로 대체하여 데이터가 업데이트 될 때 Fragment에 정보를 제공할 수 있습니다. LiveData의 가장 큰 장점은 Lifecycle을 인식하고 더 이상 필요없는 참조를 자동으로 정리합니다.
public class UserProfileViewModel extends ViewModel {
...
~~private User user;~~
private LiveData<User> user;
public LiveData<User> getUser() {
return user;
}
}
UserProfileFragment를 수정하여 데이터를 관찰하고 UI를 업데이트합니다.
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
viewModel.getUser().observe(this, user -> {
// update UI
});
}
사용자 데이터가 업데이트 될 때마다 onChanged 콜백이 호출되고 UI가 새로 고쳐집니다.
observable 콜백이 사용되는 다른 라이브러리에 익숙하다면 데이터 관찰을 중단하기 위해 프래그먼트의 onStop() 메소드를 오버라이딩 할 필요가 없다는 것을 알았을 것입니다. LiveData는 Lifecycle을 알아차리기 때문에 필요하지 않습니다. 즉, Fragment가 활성 상태(onStart()가 수신되었지만 onStop()이 수신되지 않은 경우)가 아니면 콜백을 호출하지 않습니다. Fragment가 onDestory()를 수신하면 LiveData는 옵저버를 자동으로 제거합니다.
또한 구성변경(예: 사용자 화면 회전)을 처리하기 위해 특별한 작업을 수행하지 않습니다. ViewModel은 구성이 변경되면 자동으로 복원되므로 새로운 Fragment가 생기면 ViewModel의 동일한 인스턴스를 받고 콜백이 현재 데이터로 건내줍니다. 이것이 ViewModel이 View를 직접 참조하지 않아야하는 이유입니다. View의 Lifecycle보다 오래 지속될 수 있습니다. ViewModel의 Lifecycle을 참조하세요.
데이터 가져오기
이제 ViewModel을 Fragment에 연결했지만 ViewModel이 사용자 데이터를 어떻게 가져올까요? 이 예제에서는 백엔드가 REST API를 제공한다고 가정합니다. 동일한 목적을 수행하는 다른 라이브러리를자유롭게 사용할 수 있지만 Retrofie 라이브러리를 사용하여 백엔드에 엑세스합니다.
우리의 백엔드와 통신하는 Retrofit Webservice는 다음과 같습니다.
public interface Webservice {
/**
* @GET declares an HTTP GET request
* @Path("user") annotation on the userId parameter marks it as a
* replacement for the {user} placeholder in the @GET path
*/
@GET("/users/{user}")
Call<User> getUser(@Path("user") String userId);
}
ViewModel을 네이티브하게 구현하면 Webservice를 직접 호출하여 데이터를 가져와 사용자 객체에 다시 할당할 수 있습니다. 이는 작동을 하더라도 앱이 발전함에 따라 유지보수가 어려울 수 있습니다. ViewModel 클래스에 너무 많은 책임을 주어 이전에 언급한 문제를 분리하는 원칙에 위배됩니다. 또한 ViewModel의 범위는 Activity 또는 Fragment Lifecycle과 관련되어 있어 Lifecycle이 끝나면 모든 데이터가 손실되므로 사용자 경험에 좋지 않습니다. 그렇게 때문에 ViewModel은 이 작업을 새로운 Repository module에 위임합니다.
Repository module은 데이터를 처리합니다. 그들은 어플리케이션의 나머지 부분에 순수한 API를 제공합니다. 데이터를 가져올 위치와 데이터를 업데이트 할 때 수행 할 API를 알고 있습니다. 서로 다른 데이터 소스(지속적인 모델, 웹 서비스, 캐시 등)간의 중개자로 간주 할 수 있습니다.
아래의 UserRepository 클래스는 WebService를 사용하여 사용자 데이터 항목을 가져옵니다.
public class UserRepository {
private Webservice webservice;
// ...
public LiveData<User> getUser(int userId) {
// This is not an optimal implementation, we'll fix it below
final MutableLiveData<User> data = new MutableLiveData<>();
webservice.getUser(userId).enqueue(new Callback<User>() {
@Override
public void onResponse(Call<User> call, Response<User> response) {
// error case is left out for brevity
data.setValue(response.body());
}
});
return data;
}
}
Repository 모듈은 불 필요해 보이지만 중요한 용도로 사용됩니다. 그것은 어플리케이션의 나머지 부분에서 데이터 소스를 추상화합니다. 이제 우리의 ViewModel은 Webservice가 데이터를 가져왔음을 알지 못합니다. 즉 필요에 따라 다른 구현을 위해 교환 할 수 있음을 의미합니다.
Note: 단순화을 위해 네트워크 오류 사례를 생략했습니다. 오류 및 로드 상태를 표시하는 구현의 경우 부록: 네트워크 상태 노출을 참조하세요.
구성요소간의 종속성 관리
위의 UserRepository 클래스는 작업을 수행하기 위해 Webservice 인스턴스가 필요합니다. 단순히 생성할 수는 있지마 그렇게 하기 위해서는 Webservice 클래스의 종속성을 알아야합니다. 이렇게하면 코드가 복잡해지고 복제 될 수 있습니다.(예: Webservice 인스터스가 필요한 각 클래스는 종속성을 사용하여 클래스를 생성하는 방법을 알아야합니다.) 또한 UserRepository는 아마도 Webservice가 필요한 유일한 클래스가 아닙니다. 각 클래스가 새로운 Webservice를 생성하면, 자원이 매우 무거울 것입니다.
이 문제를 해결하는데 사용할 수 있는 두가지 패턴이 있습니다.
-
Dependency Injection : Dependency Injection은 클래스가 자신의 의존성을 구성하지 않고 정의할 수 있게 해줍니다. 런타임에 다른 클래스가 이러한 종속성을 제공해야합니다. Android 앱에 Dependency Injection을 구현하기 위해 Google Dagger2 라이브러리를 사용하는 것이 좋습니다. Dagger2는 종속성 트리를 따라 이동하여 객체를 자동으로 구성하고 종속성에 대한 컴파일 시간을 보장합니다.
-
Service Locator : Service Locator는 클래스가 구성하는 대신 의존성을 얻을수 있는 레지스트리를 제공합니다. DI보다 구현이 비교적 쉽기 때문에 DI에 익숙하지 않은 경우 Service Locator를 대신 사용하세요.
이러한 패턴은 사용하면 코드를 복제하거나 복잡성을 추가히자 않고도 종속성을 관리하기 위한 명확한 패턴을 제공하므로 코드를 확장 할 수 있습니다. 둘 다 테스트를 위한 스와핑 구현을 허용합니다. 이는 이를 사용하는 주된 이점 중 하나입니다.
이 예제에서는 Dagger2를 사용하여 종속성을 관리합니다.
ViewModel과 Repository 연결하기
이제 우리는 UserProfileViewModel을 수정하여 Repository를 사용합니다.
public class UserProfileViewModel extends ViewModel {
private LiveData<User> user;
private UserRepository userRepo;
@Inject // UserRepository parameter is provided by Dagger 2
public UserProfileViewModel(UserRepository userRepo) {
this.userRepo = userRepo;
}
public void init(String userId) {
if (this.user != null) {
// ViewModel is created per Fragment so
// we know the userId won't change
return;
}
user = userRepo.getUser(userId);
}
public LiveData<User> getUser() {
return this.user;
}
}
데이터 캐싱
위의 Repository 구현은 Webservice 호출을 추상화하는 데 적합하지만 하나의 데이터 소스에만 의존하므로 매우 기능적이지 않습니다.
위의 UserRepository 구현 문제는 데이터를 가져온 후에 아무데나 유지하지 않는다는 것입니다. 사용자가 UserProfileFragment를 떠나서 다시 돌아오면 앱에서 데이터를 다시 가져옵니다. 이는 두가지 문제를 나타냅니다. 즉, 귀중한 네트워크 대역폭을 낭비하고 사용자가 새 쿼리를 완료되기까지 기다리게합니다. 이 문제를 해결하기 위해 User 객체를 메모리에 캐시하는 새로운 소스를 UserRepository에 추가합니다.
@Singleton // informs Dagger that this class should be constructed once
public class UserRepository {
private Webservice webservice;
// simple in memory cache, details omitted for brevity
private UserCache userCache;
public LiveData<User> getUser(String userId) {
LiveData<User> cached = userCache.get(userId);
if (cached != null) {
return cached;
}
final MutableLiveData<User> data = new MutableLiveData<>();
userCache.put(userId, data);
// this is still suboptimal but better than before.
// a complete implementation must also handle the error cases.
webservice.getUser(userId).enqueue(new Callback<User>() {
@Override
public void onResponse(Call<User> call, Response<User> response) {
data.setValue(response.body());
}
});
return data;
}
}
데이터 지속성
현재까지의 구현에서 사용자가 화면을 회전하거나 껏다가 앱으로 돌아오면 Repository가 메모리 내 캐시에서 데이터를 검색하기 때문에 기존 UI가 즉시 표시됩니다. 그러나 사용자가 앱을 종료하거나 나중에 안드로이드 OS가 프로세스를 죽인 후에 몇시간이 지난 후 다시오면 어떻게 될까요?
현재 이 구현에서는 네트워크에서 데이터를 다시 가져와야합니다. 이는 나쁜 사용자 경험일 뿐만 아니라 모바일 데이터를 사용하여 동일한 데이터를 다시 가져오기 때문에 낭비입니다. 웹 요청을 캐싱하여 이 문제를 해결할 수 있지만 새로운 문제가 발생합니다. 동일한 사용자 데이터가 다른 유형의 유청(예: 친구 목록 가져오기)에서 표시되면 어떻게 될까요? 그러면 앱에 일관성없는 데이터가 표시 될 수 있으며 이는 혼란스러운 사용자 환경입니다. 예를들어, 친구 목록 요청과 사용자 요청이 서로 다른 시간에 실행될 수 있기 때문에 똑같은 사용자의 데이터가 다르게 표시 될 수 있습니다. 일관성없는 데이터가 표시되지 않도록 앱을 병합해야합니다.
이것을 처리하는 올바른 방법은 지속가능한 모델을 사용하는 것입니다. 이는 Room 퍼시스턴스 라이브러리로 처리 할 수 있습니다.
Room은 최소한의 상용구 코드로 로컬 데이터 지속성을 제공하는 객체 매핑 라이브러리입니다. 컴파일 할 때 스키마에 대해 각 쿼리의 유효성을 검사하므로 깨진 SQL 쿼리는 런타임 오류 대신 컴파일 시간에 오류로 발생합니다. Room은 원시 SQL 테이블 및 쿼리로 작업하는 기본 구현 세부사항을 추상화합니다. 또한 데이터베이스 데이터(컬렉션 및 Join 쿼리 포함)에 대한 변경 사항을 관찰하고 LiveData 객체를 통해 이러한 변경사항을 노출 할 수 있습니다. 또한 메인 스레드에서 저장소에 엑세스하는 것과 같은 일반적인 문제를 해결하는 스레드 제약 조건을 명시적으로 정의합니다.
Note: SQLite 또는 Realm과 같은 다른 데이터베으스와 같은 다른 지속성 솔류션에 익숙한 경우 Room의 기능세트가 유즈-케이스와 관련이 없다면 Room을 교체할 필요는 없습니다.
Room을 사용하려면 로컬 스키마를 정의해야합니다. 먼저 @Entity로 User 클래스에 어노테이션을 달아 데이터베이스에 테이블로 표시합니다.
@Entity
class User {
@PrimaryKey
private int id;
private String name;
private String lastName;
// getters and setters for fields
}
그런 다음 앱의 RoomDatabase를 확장하여 데이터베이스 클래스를 만듭니다.
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
}
MyDatabase는 추상 클래스입니다. Room은 자동으로 그것의 구현을 제공합니다. 자세한 내용은 Room 문서를 참조하세요.
이제 사용자 데이터를 데이터베이스에 삽입하는 방법이 필요합니다. 이를 위해 데이터 엑세스 객체(DAO)를 만듭니다.
@Dao
public interface UserDao {
@Insert(onConflict = REPLACE)
void save(User user);
@Query("SELECT * FROM user WHERE id = :userId")
LiveData<User> load(String userId);
}
그런 다음 데이터베이스 클래스에서 DAO를 참조하세요.
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
public abstract UserDao userDao();
}
load(String)은 LiveData<User>를 반환합니다. Room은 데이터베이스가 수정된 시점을 알고 있으며 데이터가 변경되면 모든 활성된 관찰자에게 자동으로 알립니다. LiveData를 사용하기 때문에 적어도 하나의 활성된 관찰자가 있는 경우에만 데이터를 업데이트하므로 효율적입니다.
Note: 알파 1버전에서 Room은 테이블 수정을 기반으로 무효를 확인합니다. 이는 잘못된 긍정적 알림을 발송 할 수 있음을 의미합니다.
이제 Room 데이터 소스를 통합하도록 UserRepository를 수정해야합니다.
@Singleton
public class UserRepository {
private final Webservice webservice;
private final UserDao userDao;
private final Executor executor;
@Inject
public UserRepository(Webservice webservice, UserDao userDao, Executor executor) {
this.webservice = webservice;
this.userDao = userDao;
this.executor = executor;
}
public LiveData<User> getUser(String userId) {
refreshUser(userId);
// return a LiveData directly from the database.
return userDao.load(userId);
}
private void refreshUser(final String userId) {
executor.execute(() -> {
// running in a background thread
// check if user was fetched recently
boolean userExists = userDao.hasUser(FRESH_TIMEOUT);
if (!userExists) {
// refresh the data
Response response = webservice.getUser(userId).execute();
// TODO check for error etc.
// Update the database.The LiveData will automatically refresh so
// we don't need to do anything else here besides updating the database
userDao.save(response.body());
}
});
}
}
UserRepository에서 데이터가 어디에서 왔는지를 변경했더라도 UserProfileViewModel 또는 UserProfileFragment를 변경할 필요가 없었습니다. 이는 추상화가 제공하는 유연성입니다. UserProfileViewModel을 테스트하는 동안 위조된 UserRepository를 제공할 수 있기 때문에 테스트에도 좋습니다.
이제 코드가 완성되었습니다. 사용자가 나중에 동일한 UI로 돌아오면 사용자 정보가 계속 유지되므로 사용자 정보를 즉시 볼 수 있습니다. 한편, 우리의 Repository는 데이터가 오래되면 백그라운에서 데이터를 업데이트합니다. 물론, 유즈-케이스에 따라 너무 오래 걸리는 경우 지속된 데이터를 표시하지 않을 수도 있습니다.
새로고침(pull-to-refresh)와 같은 일부 유즈-케이스에서는 진행중인 네트워크 작업이 있는 경우 사용자에게 UI를 표시하는 것이 중요합니다. UI작업을 여러가지 이유로 업데이트 할 수 있으므로 UI작업을 실제 데이터와 분리하는 것이 좋습니다.(예: 친구 목록을 가져오면 같은 사용자가 다시 가져와 LiveData
이 유즈-케이스에는 두 가지 공통적인 솔루션이 있습니다.
- getUser를 수정하여 네트워크 작업상태를 표시하는 LiveData를 반환합니다. 이에는 부록: 네트워크 상태 노출 세션에서 구현된 예가 제공됩니다.
- 사용자의 새로고침 상태를 반환 할 수 있는 Repository 클래스에 다른 public 함수를 제공합니다. 이 옵션은 명시적 사용자 조치(예: 새로고침(pull-to-refresh))에 대한 응답으로 UI에 네트워크 상태를 표시하는 경우 더 좋습니다.
Single source of truth
다른 REST API 엔드 포인트가 동일한 데이터를 리턴하는 것이 일반적입니다. 예를 들어, Google의 백엔드에 친구 목록을 반환하는 다른 엔드 포인트가 있는 경우 동일한 사용자 객체가 두 개의 서로 다른 API 엔드 포인트에서 왔을 수 있습니다.(아마도 세분화되어 있을 수 있습니다) UserRepository가 Webservice 요청의 응답을 그대로 반환하는 경우 UI가 데이터 요청이 발생할 때마다 서버 측에서 변경이 될 수 있기 때문에 일관성없는 데이터가 표시될 수 있습니다. 이것이 UserRepository 구현에서 Webservice 콜백이 데이터를 데이터베이스에 저장하는 이유입니다. 그런 다음 데이터베이스를 변경하면 활성된 LiveData 객체에 대한 콜백이 트리거됩니다.
이 모델에서 데이터베이스는 단일 소스 근원으로 사용되며 앱의 다른 부분은 Repository를 통해 엑세스됩니다. 디스크 캐시를 사용하는지 여부에 관계없이 Repository에서 나머지 데이터 소스에 대한 단일 소스로 데이터 소스를 지정하는 것이 좋습니다.
테스트
우리는 분리의 이점 중 하나가 테스트 가능성이라고 언급했습니다. 각 코드 모듈을 테스트하는 방법을 살펴 보겠습니다.
-
User Interface & Interactions: Android UI 계측 테스트가 필요한 유일한 시간입니다. UI 코드를 테스트하는 가장 좋은 방법은 Espresso 테스트를 만드는 것입니다. Fragment를 만들고 mock ViewModel을 제공 할 수 있습니다. Fragment는 ViewModel과만 통신하기 때문에 mock하면 UI를 완전히 테스트하는 것으로 충분합니다.
-
ViewModel: ViewModel은 JUnit 테스트를 사용하여 테스트 할 수 있습니다. 테스트를 위해 UserRepository만 mock해야합니다.
-
UserRepository: JUnit 테스트로
UserRepository를 테스트 할 수 있습니다.Webservice와 DAO를 mock 해야합니다. 적절한 웹 서비스 호출을 만들고 데이터를 데이터베이스에 저장하며 데이터가 캐시되고 최신 상태이면 불필요한 요청을 하지 않는지 테스트 할 수 있습니다.Webservice와UserDAO가 모두 인터페이스이기 때문에 좀 더 복잡한 테스트 케이스를 위해 모방하거나 가짜 구현을 만들 수 있습니다. -
UserDAO: DAO 클래스를 테스트 할 때 권장되는 방법은 계측 테스트를 사용하는 것입니다. 이러한 계측 테스트에는 UI가 필요하지 않으므로 빠르게 실행됩니다. 각 테스트마다 인 메모리 데이터베이스를 만들어 디스크에 데이터베이스 파일을 변경하는 것과 같은 부작용이 테스트에 없도록 할 수 있습니다. 또한 데이터베이스 구현을 지정하여 SupportSQLiteOpenHelper의 JUnit 구현을 제공하여 이를 테스트 할 수 있습니다. 장치에서 실행되는 SQLite 버전이 호스트 컴퓨터의 SQLite 버전과 다를 수 있으므로 이 방법은 일반적으로 권장되지 않습니다.
-
Webservice: 외부 세계와 독립적으로 테스트르 수행하는 것이 중요하므로
Webservice테스트에서도 백엔드에 네트워크 호출을 하지 않아야합니다. 이것에 도움되는 라이브러리가 많이 있습니다. 예를 들어, MockWebServer는 테스트를 위해 까자 로컬 서버를 만드는데 도움이 되는 훌륭한 라이브러리입니다. -
Testing Artifacts Architecture Components는 백그라운드 스레드를 제어하기 위해 메이븐 아티팩트를 제공합니다.
android.arch.core:core-testing아티팩트에는 두가지 JUnit 규칙이 있습니다.InstantTaskExecutorRule: 이 규칙은 아키텍쳐 구성요소가 호출 스레드에서 모든 백그라운드 작업을 즉시 실행할 수 있도록 하는데 사용 할 수 있습니다.CountingTaskExecutorRule: 이 규칙은 계측 테스트에서 아키텍쳐 구성요소의 백그라운드 작업을 기다리고나 idie 리소스로 Espresso에 연결하는데 사용 할 수 있습니다.
최종 아키텍쳐
다음 다이어그램은 권장 아키텍쳐의 모든 모듈과 모듈 상호 작용 방식을 보여줍니다.
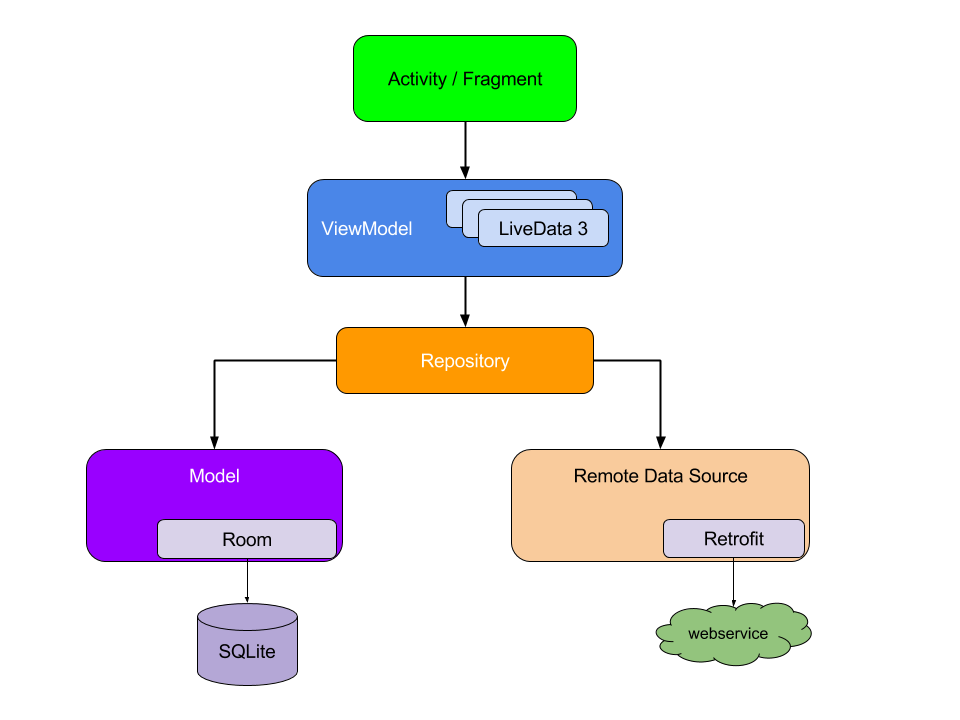
지침 원칙
프로그래밍은 창조적인 분야이며, Android 앱을 개발하는 것도 예외는 아닙니다. 문제를 해결하는 방법에는 여러가지 방법이 있습니다. 즉, 여러 Activity 또는 Fragmenet 같에 데이터를 주고 받고, 원격 데이터를 검색하고 오프라인 모드에서 로컬로 유지하거나, 사소한 응용 프로그램에서 발생하는 여러가지 일반적인 시나리오가 있습니다.
다음 권장 사항은 필수 사항은 아니자만 장기간에 컬쳐 코드베이스를 보다 견고하고 테스트 가능하며 유지 관리가 가능하게 만드는 것이 우리의 경험이 있습니다.
- 매니페스트에 정의한 진입점(Activity, Service, Broadcase recevier등)은 데이터 소스가 아닙니다. 대신 엔트리 포인트와 관련된 데이터의 부분집합을 조정해야합니다. 사용자의 기기와 상호작용 및 런타임의 전반적인 상태에 따라 각 앱 구성요소의 수명이 짧기 때문에 이러한 진입점이 데이터 소스가 되기를 원하지 않습니다.
- 앱의 다양한 모듈간의 명확한 책임의 경게를 만드는데 무자비한 태도를 취하세요. 예를 들어 네트워크의 데이터를 로드하는 코드를 코드 기반의 여러 클래스 또는 패키지로 분산시키지 마세요. 마찬가지로, 데이터 캐싱 및 데이터 바인딩과 같은 관련없는 책임을 같은 클래스에 채우지 마세요.
- 가능한 한 각 모듈에서 노출 시키세요. 하나의 모듈에서 내부 구현 세부사항을 드러내는 “바로 그 하나”의 바로가기를 만들려고 시도하지 마세요. 단기간에 약간의 시간을 얻을 수도 있지만 코드베이스가 발전함에 따라 기술 부채를 여러 번 지불하게 됩니다.
- 모듈간의 상호작용을 정의 할 때 각 모듈을 개별적으로 테스트 할 수 있게 만드는 방법에 대해서 생각하세요. 예를 들어, 네트워크에서 데이터를 가져오기 위한 잘 정의된 API를 사용하면 해당 데이터를 로컬 데이터베이스에 유지하는 모듈을 보다 쉽게 테스트 할 수 있습니다. 대신, 이 두 모듈의 로직을 한 곳에서 혼합하거나 전체 코드 기반에 네트워킹 코드를 뿌리면 불가능하지는 않더라도 테스트하는 것이 훨씬 더 어려워 질 것입니다.
- 앱의 핵심은 나머지 부분과 눈에 띄는 점입니다. 동일한 상용구 코드를 반복해서 구현하는데 시간을 낭비하지 마세요. 대신 자신의 앱을 독창적으로 만드는데 집중하여 Android Architecture 구성 요소 및 기타 권장 라이브러리에서 반복적인 사용구를 처리하도록하세요.
- 기기가 오프라인 모드 일 때 앱을 사용 할 수 있도록 가능한 한 관련성이 높고 신선한 데이터를 유지합니다. 일정하고 고속의 연결을 즐길 수는 있지만 사용자는 그렇지 않을 수도 있습니다.
- Repository는 하나의 데이터 소스를 단일 진원으로 지정해야합니다. 앱이 이 데이터에 엑세스 할 때 마다 항상 단일 근원에서 비롯됩니다. 자세한 내용은 Single source of truth을 참조하세요.
부록: 네트워크 상태 노출
위의 권장 앱 아키텍쳐 세션에서 샘플을 간단하게 유지하기 위해 의도적으로 네트워크 오류 및 로드상태를 생략했습니다. 이 절에서는 Resource 클래스를 사용하여 네트워크 상태를 노출하여 데이터와 상태를 캡슐화하는 방법을 보여줍니다.
다음은 샘플 구현입니다.
//a generic class that describes a data with a status
public class Resource<T> {
@NonNull public final Status status;
@Nullable public final T data;
@Nullable public final String message;
private Resource(@NonNull Status status, @Nullable T data, @Nullable String message) {
this.status = status;
this.data = data;
this.message = message;
}
public static <T> Resource<T> success(@NonNull T data) {
return new Resource<>(SUCCESS, data, null);
}
public static <T> Resource<T> error(String msg, @Nullable T data) {
return new Resource<>(ERROR, data, msg);
}
public static <T> Resource<T> loading(@Nullable T data) {
return new Resource<>(LOADING, data, null);
}
}
네트워크에서 데이터를 도르하면서 디스크에서 로드하는 것이 일반적인 경우이기 때문에 우리는 여러 곳에서 재 소용 할 수 있는 도우미 클래스인 NetworkBoundResource를 만들 예정입니다. 아래는 NetworkBoundResouce의 의사 결정 트리입니다.
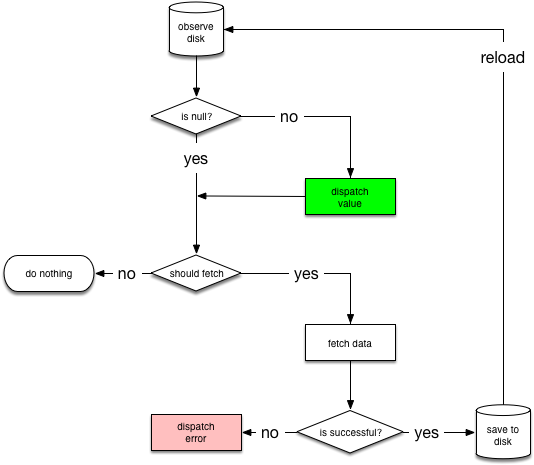
이것은 Resource에 대한 데이터베이스를 관찰하여 시작합니다. 항목이 데이터베이스에서 처음 로드되면 NetworkBoundResouce는 결과가 전달되기에 충분한지 또는 네트워크에서 가져와야하는지 여부를 확입합니다. 캐시된 데이터를 네트워크에서 업데이트하는 동안 표시하려는 것은 둘 다 동시에 발생할 수 있습니다.
네트워크 호출이 성공적으로 완료되면 응답을 데이터베이스에 저장하고 스트림을 다시 초기화합니다. 네트워크 요청이 실패하면 직접 실패를 처리합니다.
Note: 새 데이터를 디스크에 저장 한 후에는 데이터베이스에서 스트림을 다시 초기화하지만 일반적으로 데이터베이스에서 스트림을 변경하므로 스트림을 다시 만들 필요가 없습니다. 반면에 변경 사항을 전달하기 위해 데이터베이스에 의존하는 것은 데이터가 변경되지 않았을때 데이터베이스가 변경 사항을 전달하는 것을 피할 수 있으면 중단 될 수 있으므로 부작용에 의존하게됩니다. 우리는 네트워크에서 도착한 결과를 전달하기를 원하지 않습니다. 그 이유는 이것이 단일 소스 진원(아마도 데이터베이스에 저장 값을 변경시키는 트리거가 있을 수도 있습니다.)에 맞서기 때문입니다. 또한 클라이언트에게 잘못된 정보를 보낼 것이기 때문에 새로운 데이터 없이 SUCCESS를 보내고 싶지 않습니다.
다음은 NetworkBoundResouce 클래스에서 제공하는 public API 입니다.
// ResultType: Type for the Resource data
// RequestType: Type for the API response
public abstract class NetworkBoundResource<ResultType, RequestType> {
// Called to save the result of the API response into the database
@WorkerThread
protected abstract void saveCallResult(@NonNull RequestType item);
// Called with the data in the database to decide whether it should be
// fetched from the network.
@MainThread
protected abstract boolean shouldFetch(@Nullable ResultType data);
// Called to get the cached data from the database
@NonNull @MainThread
protected abstract LiveData<ResultType> loadFromDb();
// Called to create the API call.
@NonNull @MainThread
protected abstract LiveData<ApiResponse<RequestType>> createCall();
// Called when the fetch fails. The child class may want to reset components
// like rate limiter.
@MainThread
protected void onFetchFailed() {
}
// returns a LiveData that represents the resource
public final LiveData<Resource<ResultType>> getAsLiveData() {
return result;
}
}
API에서 리턴된 데이터 유형이 로컬에서 사용되는 데이터 유형과 일치하지 않을 수 있으므로 위 클래스는 두 유형의 매개변수(ResultType, ResultType)을 정의합니다.
또한 위 코드는 네트워크 요청에 ApiResponce를 사용합니다. ApiResponce는 응답을 LiveData로 변환하는 Retrofit2.Call 클래스를 둘러싼 간단한 래퍼 클래스입니다.
다음은 NetworkBoundResouce 클래스의 나머지 구현부분입니다.
public abstract class NetworkBoundResource<ResultType, RequestType> {
private final MediatorLiveData<Resource<ResultType>> result = new MediatorLiveData<>();
@MainThread
NetworkBoundResource() {
result.setValue(Resource.loading(null));
LiveData<ResultType> dbSource = loadFromDb();
result.addSource(dbSource, data -> {
result.removeSource(dbSource);
if (shouldFetch(data)) {
fetchFromNetwork(dbSource);
} else {
result.addSource(dbSource,
newData -> result.setValue(Resource.success(newData)));
}
});
}
private void fetchFromNetwork(final LiveData<ResultType> dbSource) {
LiveData<ApiResponse<RequestType>> apiResponse = createCall();
// we re-attach dbSource as a new source,
// it will dispatch its latest value quickly
result.addSource(dbSource,
newData -> result.setValue(Resource.loading(newData)));
result.addSource(apiResponse, response -> {
result.removeSource(apiResponse);
result.removeSource(dbSource);
//noinspection ConstantConditions
if (response.isSuccessful()) {
saveResultAndReInit(response);
} else {
onFetchFailed();
result.addSource(dbSource,
newData -> result.setValue(
Resource.error(response.errorMessage, newData)));
}
});
}
@MainThread
private void saveResultAndReInit(ApiResponse<RequestType> response) {
new AsyncTask<Void, Void, Void>() {
@Override
protected Void doInBackground(Void... voids) {
saveCallResult(response.body);
return null;
}
@Override
protected void onPostExecute(Void aVoid) {
// we specially request a new live data,
// otherwise we will get immediately last cached value,
// which may not be updated with latest results received from network.
result.addSource(loadFromDb(),
newData -> result.setValue(Resource.success(newData)));
}
}.execute();
}
}
이제 우리는 NetworkBoundResouce를 사용하여 디스크 및 네트워크 바인딩을 이용하여 User의 처리를 Repository에 구현 할 수 있습니다.
class UserRepository {
Webservice webservice;
UserDao userDao;
public LiveData<Resource<User>> loadUser(final String userId) {
return new NetworkBoundResource<User,User>() {
@Override
protected void saveCallResult(@NonNull User item) {
userDao.insert(item);
}
@Override
protected boolean shouldFetch(@Nullable User data) {
return rateLimiter.canFetch(userId) && (data == null || !isFresh(data));
}
@NonNull @Override
protected LiveData<User> loadFromDb() {
return userDao.load(userId);
}
@NonNull @Override
protected LiveData<ApiResponse<User>> createCall() {
return webservice.getUser(userId);
}
}.getAsLiveData();
}
}